
The rapidly evolving field of artificial intelligence presents a dynamic battleground for strategies aimed at customizing large language models (LLMs) for specific tasks. Two prominent methodologies have emerged: fine-tuning and in-context learning (ICL). Recent investigations by the combined expertise of Google DeepMind and Stanford University illuminate not only the strengths and weaknesses of these two approaches but also propose a hybrid method that marries their benefits. The implications of their findings are profound for developers seeking to harness LLMs in environments laden with specialized enterprise data.
Fine-tuning is a methodology that modifies a pre-trained model by training it further on a more specialized dataset. This recalibration of internal parameters allows the model to learn new skills or absorb fresh knowledge. In contrast, ICL eschews the infamous parameter adjustment process. Instead, it employs prompt engineering, utilizing the model’s existing capabilities to make inferences based on examples provided within the input. While fine-tuning has a reputation for adapting models to new data effectively, ICL exhibits superior generalization—at the cost of increased computational demands during inference.
A Rigorous Comparison of Generalization Capabilities
Researchers’ efforts to dissect the generalization abilities of fine-tuning versus ICL led to the creation of meticulously-designed synthetic datasets. These datasets were populated with complex, self-consistent data structures, including fictitious hierarchies and invented family trees. In conducting their experiments, researchers ensured that models were tested under conditions that demanded original inferencing abilities. By using nonsense terms, they effectively isolated the learning capabilities from previously encountered data, allowing for a fresh evaluation of each model’s generalization prowess.
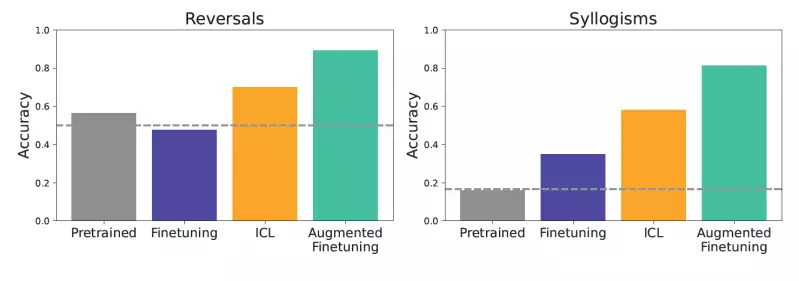
The tested scenarios included basic reversals and syllogistic reasoning. A model trained with the statement “femp are more dangerous than glon” was evaluated on its capacity to deduce that “glon are less dangerous than femp.” In cases of syllogisms like “All glon are yomp” along with “All troff are glon,” the ability to derive “All troff are yomp” was put to the test. Ultimately, the models utilizing ICL outperformed their fine-tuned counterparts, demonstrating a heightened aptitude for tasks that required complex deductions.
The Trade-Offs of Computational Costs
One of the fascinating insights from the study is centered around computational costs associated with the two methods. ICL emerges as a formidable player in generalization but at the expense of higher inference costs. Yet, in scenarios where models were not fine-tuned or did not utilize ICL, performance plummeted, underscoring the necessity of these advanced strategies.
Andrew Lampinen, a research scientist at Google DeepMind and the lead author of the study, emphasized that while ICL saves on training, it leads to increased computational requirements when deployed in practical applications. On the other hand, fine-tuning excels in terms of lower computational demands but may yield insufficient generalization without the cognitive flexibility that ICL offers.
The Promising Blend: Augmented Fine-Tuning
From their discoveries, the researchers championed an innovative approach to optimize fine-tuning by harnessing ICL methodologies to generate richer datasets. This augmented fine-tuning involves two data augmentation strategies: local and global. The local approach involves generating diverse examples through rephrasing original training data, while the global strategy includes providing the entire dataset to enable complex inference crafting.
The results from implementing this hybrid technique were significant, showcasing markedly improved generalization compared to both standard fine-tuning and unadulterated ICL implementations. For example, when leveraging augmented datasets, models were better equipped to handle inquiries about complex enterprise tools—indicating practical applications in corporate environments that hinge on accurate, context-aware responses.
The Future Landscape of Language Model Development
As the landscape of artificial intelligence continues to expand, the choices developers make in customizing LLMs will become increasingly crucial. Investing in creating ICL-augmented datasets can facilitate the development of models that deliver superior performance across different contexts and queries. This dual advantage of enhanced generalization while mitigating continuous inference costs presents a compelling value proposition for enterprises.
Although augmented fine-tuning may initially appear to incur higher costs due to the additional step of generating inferences, saving on long-term inference costs can result in better resource management over the model’s usage life. As organizations deploy these advanced AI models, the research suggests a path forward where the meticulous balancing of training efficiency and operational performance becomes paramount.
The research consequently urges developers to reassess established methods in light of these emerging findings. By exploring augmented fine-tuning, developers may unlock the full potential of LLMs, striving for not only higher accuracy but also a more profound understanding of the complex interplay between training methods and performance in real-world applications. The advances made in this research stand to significantly shift how AI can be leveraged for dynamic problem-solving in various industries.